Spark Streaming과 Kafka연동

Spark Streaming 개요
Spark Streaming이란?
- 실시간 데이터 처리를 위한 Spark API
- Kafka, Kinesis, Flume, TCP 소켓 등의 다양한 소스에서 데이터를 수집하고 처리 가능
- Join, Map, Reduce, Window 등 다양한 연산 지원

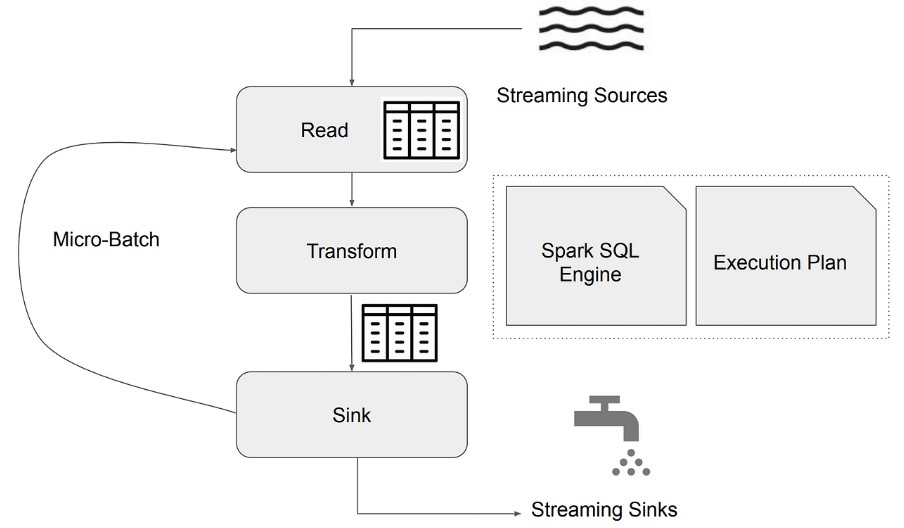
Spark Streaming 동작 방식
- 데이터를 마이크로 배치로 나누어 처리
- 처리된 데이터는 이전 데이터와 병합하여 지속적인 분석 가능
- 배치마다 데이터 위치 관리 (오프셋 기반 데이터 추적)
- Fault Tolerance 및 데이터 재처리 지원
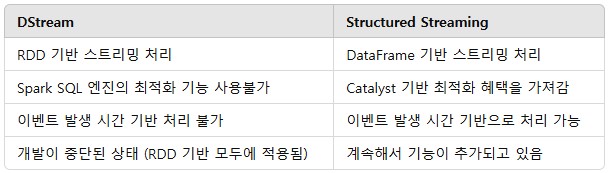
Spark Structured Streaming
- DStream 기반의 기존 Spark Streaming을 개선한 API
- 실시간 스트림 데이터를 DataFrame 형태로 처리
- 배치 처리와 동일한 API를 사용하여 유지보수 용이
- 강력한 Exactly-Once 처리 보장 및 자동 장애 복구 지원
Source & Sink
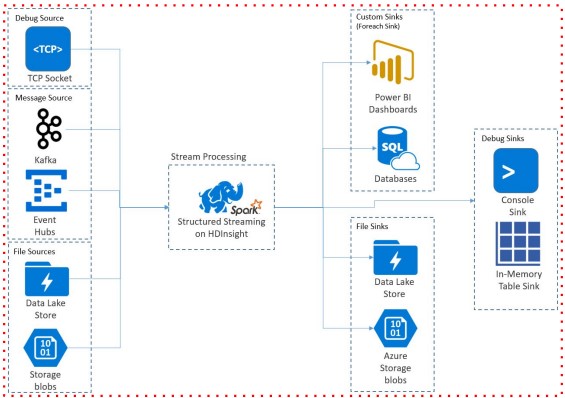
Source (데이터 입력)
- 외부 시스템에서 데이터를 읽어오는 역할
- Kafka, Amazon Kinesis, Apache Flume, TCP/IP 소켓, HDFS, 파일 시스템 등 다양한 소스 지원
- 데이터를 Spark DataFrame으로 변환하여 처리 가능
lines_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "test-topic") \
.load()Sink (데이터 출력)
- 처리된 데이터를 외부 시스템으로 저장하는 역할
- Kafka, HDFS, Amazon S3, Apache Cassandra, JDBC 데이터베이스 등에 저장 가능
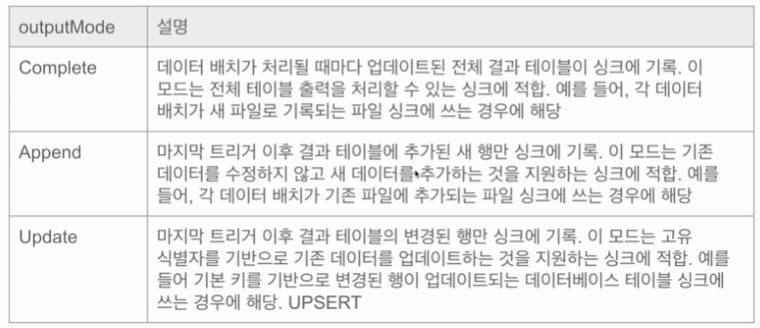
- outputMode를 통해 데이터 저장 방식 결정
- Append: 새 데이터만 추가
- Update: 변경된 데이터만 반영 (UPSERT 개념)
- Complete: 전체 데이터를 덮어쓰기 (FULL REFRESH)
word_count_query = counts_df.writeStream \
.format("console") \
.outputMode("complete") \
.option("checkpointLocation", "chk-point-dir") \
.start()Micro Batch Trigger Option
- Micro Batch Trigger Option 문서
- Unspecified: 디폴트 모드. 현재 Micro Batch가 끝나면 다음 Batch가 바로 시작
- Time Interval: 고정된 시간마다 Micro Batch를 시작
- 현재 Batch가 지정된 시간을 넘어서 끝나면 끝나자마자 다음 Batch가 시작됨
- 읽을 데이터가 없는 경우 시작되지 않음
- One Time => Available-Now: 지금 있는 데이터를 모두 처리하고 중단
- Continuous: 새로운 저지연 연속 처리 모드에서 실행
# Default trigger (runs micro-batch as soon as it can)
df.writeStream \
.format("console") \
.start()
# ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream \
.format("console") \
.trigger(processingTime='2 seconds') \
.start()
# Available-now trigger
df.writeStream \
.format("console") \
.trigger(availableNow=True) \
.start()
# Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()Streaming WordCount 예제
실시간 단어 개수 세기 (WordCount)
- WordCount Spark 문서
- Spark에서 제공하는 예제 프로그램을 활용
- TCP 소켓에서 수신 대기 중인 데이터 서버로부터 수신한 텍스트 데이터의 단어 수를 세어줌
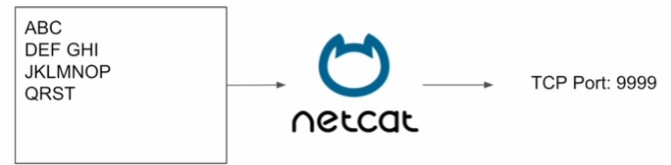
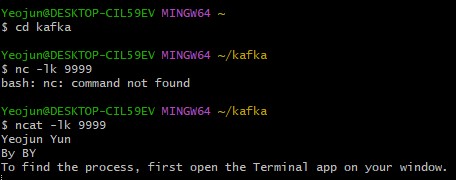
데이터 Producer 실행 (터미널 1)
- Netcat을 사용해서 텍스트 스트림을 생성(우리가 타입하는 텍스트 바탕)
- Netcat을 포트번호 9999번에 데이터를 보내도록 실행
- 입력한 테스트는 모두 TCP 9999번으로 보내짐
ncat -lk 9999

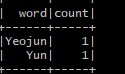
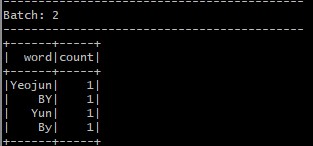
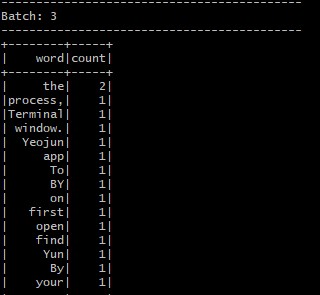
Data Consumer 실행 (터미널 2)
- 체크포인트는 Fault Tolerance와 Exactly Once를 가능하게 하는 Spark 구조화된 스트리밍의 메커니즘
- 스트리밍 쿼리와 메타데이터와 상태 정보가 있음
- HDFS또는 S3와 같은 안정적인 스토리지 시스템에 일정한 간격으로 저장
더보기
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Streaming Word Count") \
.master("local[3]") \
.config("spark.streaming.stopGracefullyOnShutdown", "true") \
.config("spark.sql.shuffle.partitions", 3) \
.getOrCreate()
# READ
lines_df = spark.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", "9999") \
.load()
# TRANSFORM
words_df = lines_df.select(expr("explode(split(value,' ')) as word"))
words_df.createOrReplaceTempView("words_table")
counts_df = spark.sql("""
SELECT word, COUNT(*) count
FROM words_table
GROUP BY word
""")
# counts_df = words_df.groupBy("word").count()
# SINK
word_count_query = counts_df.writeStream \
.format("console") \
.outputMode("complete") \
.option("checkpointLocation", "chk-point-dir") \
.start()
print("Listening to localhost:9999")
word_count_query.awaitTermination()Kafka와 Spark Streaming 연동

Spark Streaming + Kafka 다이어그램
- Kafka에서 데이터를 읽어와 Spark Structured Streaming으로 처리
- 처리된 데이터를 다시 Kafka 또는 다른 Sink로 저장
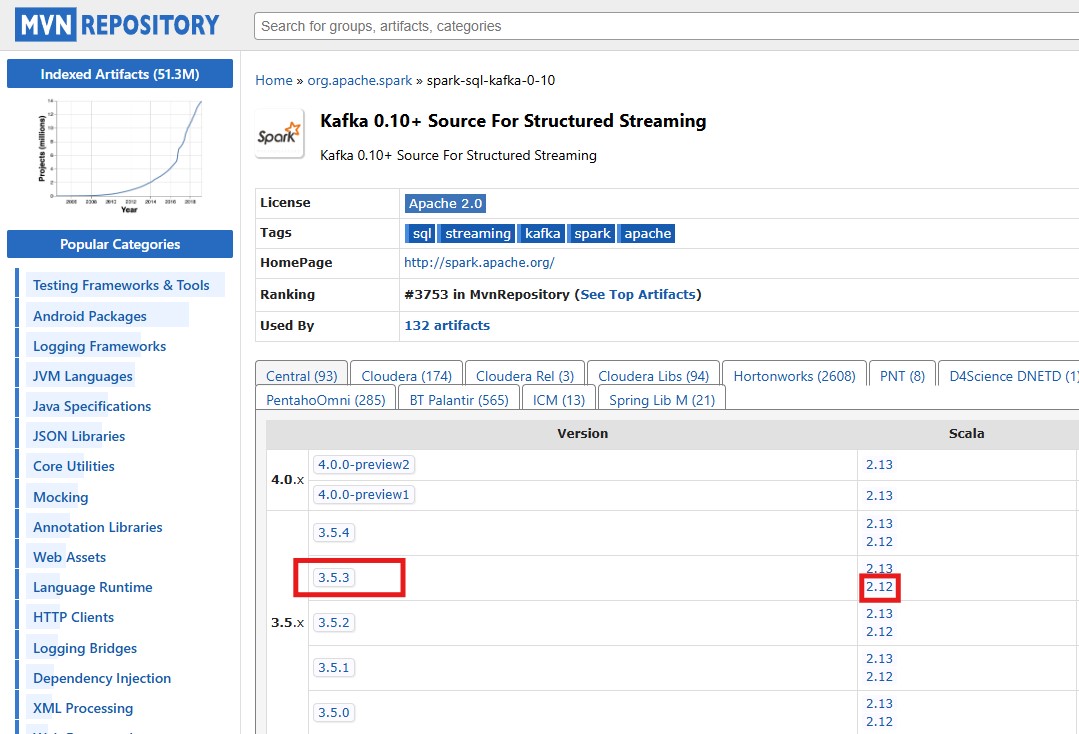
Kafka Structured Streaming 실행 준비
- Spark에서 Kafka를 사용하려면 spark.jars.packages 설정 필요
- 설정 방법
- spark-defaults.conf 파일 수정
- SparkSession 생성 시 config 지정
- spark-submit 실행 시 --packages 옵션 사용
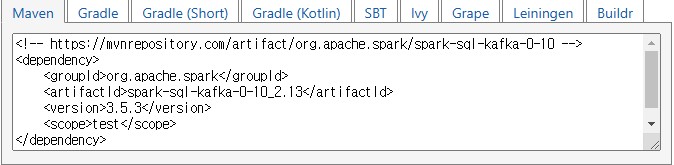
spark-submit 명령어 예제
spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.3 kafka_source_streaming.pyKafka 데이터 처리 예제 (Title 빈도 분석)
- fake_people 토픽에서 가장 많이 등장하는 title 계산
더보기
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col, expr
from pyspark.sql.types import StructType, StructField, StringType, LongType, DoubleType, IntegerType, ArrayType
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("File Streaming Demo") \
.master("local[3]") \
.config("spark.streaming.stopGracefullyOnShutdown", "true") \
.getOrCreate()
schema = StructType([
StructField("id", StringType()),
StructField("name", StringType()),
StructField("title", StringType())
])
kafka_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "fake_people") \
.option("startingOffsets", "earliest") \
.load()
kafka_df.printSchema()
"""
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
"""
value_df = kafka_df.select(from_json(col("value").cast("string"), schema).alias("value"))
value_df.createOrReplaceTempView("fake_people")
value_df.printSchema()
count_df = spark.sql("SELECT value.title, COUNT(1) count FROM fake_people GROUP BY 1 ORDER BY 2 DESC LIMIT 10")
count_writer_query = count_df.writeStream \
.format("console") \
.outputMode("complete") \
.option("checkpointLocation", "chk-point-dir-json") \
.start()
print("Listening to Kafka")
count_writer_query.awaitTermination()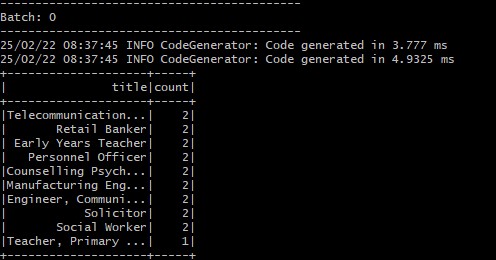
※ 출처가 기재되지 않은 이미지는 프로그래머스 데브코스 데이터 엔지니어링입니다.
'Kafka & Spark Streaming' 카테고리의 다른 글
| Kafka 기본 프로그래밍 (0) | 2025.02.22 |
|---|---|
| Kafka 주요 기능과 설치 및 간단한 실습 (1) | 2025.02.21 |
| Kafka소개 (0) | 2025.02.21 |
| 실시간 데이터 처리 소개 (0) | 2025.02.20 |