Kafka 주요 기능
Kafka 주요 기능 살펴보기

Kafka Connect란?
Kafka Connect는 Kafka 위에 구축된 중앙 집중형 데이터 허브로, 데이터 시스템 간의 데이터를 주고받는 데 사용된다. 이를 통해 Kafka를 데이터 버스 또는 메시지 버스로 활용할 수 있다.
- 두 가지 모드 제공
- Standalone 모드: 개발 및 테스트 용도
- Distributed 모드: 실제 운영 환경
- Kafka를 통해 다양한 데이터 시스템을 연결 가능
- 데이터 소스 예시: 데이터베이스, 파일 시스템, 키-값 저장소, 검색 인덱스 등
- 데이터 싱크 예시: S3 버킷, 데이터 웨어하우스 등
- Broker 일부 또는 별도 서버에서 실행 가능
- Worker들이 Task를 수행하며 Producer/Consumer 역할
- Source Task: 외부 데이터를 Kafka 이벤트 스트림으로 읽어옴
- Sink Task: Kafka 데이터를 외부 시스템으로 내보냄

Kafka Schema Registry
Kafka Schema Registry는 Kafka 메시지 데이터의 스키마를 관리하고 검증하는 역할을 한다.
- 스키마 관리 및 버전 지원
- 주로 Avro 형식 사용(또는 Protobuf, JSON)
- Schema ID(버전)를 통해 스키마 변화를 지원 (Schema Evolution)
- 스키마 변경 방식
- Forward Compatibility: Producer 먼저 변경 → Consumer 점진적 변경
- Backward Compatibility: Consumer 먼저 변경 → Producer 점진적 변경
- Full Compatibility: Producer와 Consumer 동시 변경
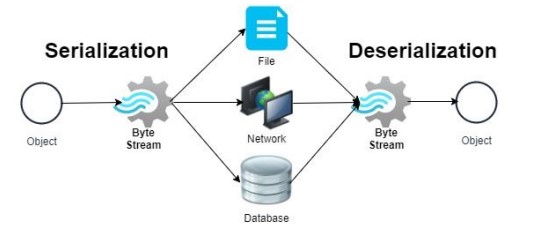
Serialization & Deserialization
Kafka에서는 데이터를 전송할 때 직렬화(Serialization) 및 역직렬화(Deserialization)를 수행한다.
- 직렬화(Serialization): 객체 데이터를 전송 가능하도록 변환 (데이터 압축 포함 가능)
- 역직렬화(Deserialization): 받은 데이터를 원래의 형태로 변환하여 사용
- Kafka 라이브러리에서 기본적으로 처리

REST Proxy
Kafka REST Proxy는 API 호출을 통해 Kafka에 접근할 수 있도록 해준다.
- 주요 기능
- 메시지 생성 및 소비
- 토픽 관리
- 메시지 직렬화 및 역직렬화 수행
- 로드 밸런싱 지원
- 활용 예시: 외부 네트워크에서 Kafka 클러스터에 접근해야 하는 경우 유용함
Kafka Streams
Kafka Streams는 실시간 스트림 처리를 위한 Kafka 라이브러리다.
- 특징
- Kafka Topic을 소비 및 생성 가능
- Spark Streaming보다 더 실시간(레코드 단위) 처리 가능
- 별도 클러스터 없이 실행 가능 (Kafka 내부에서 실행)

ksqlDB
ksqlDB는 Kafka Streams 기반의 스트림 처리 데이터베이스다.
- 주요 기능
- SQL과 유사한 쿼리 언어 지원
- 필터링, 집계, 조인, 윈도우 연산 가능
- 연속 쿼리 지원 (실시간 데이터 처리)
- 지속적으로 업데이트되는 뷰 제공
Kafka 설치 및 간단한 실습
Kafka 설치 방법
Kafka 설치 방식
Kafka는 여러 방법으로 설치할 수 있으며, 가장 간편한 방법은 Docker Compose를 이용하는 것이다.
- Docker Compose 사용
- Docker Desktop을 실행한 후, 다음 명령어 실행
# bash에서
git clone https://github.com/conduktor/kafka-stack-docker-compose.git
cd kafka-stack-docker-compose
docker compose -f full-stack.yml up


- Kafka 웹 콘솔 접속
- Connect WebUI: localhost:8080
- 로그인 정보: admin@admin.io / admin
Kafka Python 프로그래밍
Kafka는 다양한 프로그래밍 언어를 지원한다.
- Java: Apache Kafka Java Client, Spring Kafka
- Python: Confluent Kafka Python, kafka-python
- .NET: Confluent Kafka .NET Client
- Go: Sarama
- Node.js: node-rdkafka, kafka-node
Kafka Producer (Python)
# 아래 예제는 KafkaProducer를 사용하여 0.5초마다 메시지를 전송하는 코드이다.
# 로컬 Kafka 인스턴스를 연결하는 KafkaProducer 객체를 생성
# 전송하려는 데이터를 json 문자열로 변환한 다음 UTF-8로 인코딩하여 직렬화하는 방법을 정의
# 0.5초마다 "topic-test"라는 토픽과 반복 카운터를 데이터로 포함하는 이벤트를 전송
# 데이터는 'counter'라는 키와 정수를 값으로 갖도록 구성
from time import sleep
from json import dumps
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8')
)
for j in range(999):
print("iteration", j)
data = {'counter': j}
producer.send('topic_test', value=data)
sleep(0.5)Kafka Consumer (Python)
# 아래 예제는 KafkaConsumer를 사용하여 토픽 데이터를 소비하는 코드이다.
# 로컬 Kafka 인스턴스를 연결하는 KafkaConsumer객체를 생성
# "topic_test"토픽에서 가장 먼저 생긴 데이터부터 읽고 오프셋 정보는 계속해서 업데이트함
# my-group-id라는 이름의 consumer group에 조인하도록 설정
# 2초마다 "topic-test"라는 토픽에서 카운터 값을 읽도록 구성
# earliest vs latest: 가장 최신 vs 가장 일찍
# enable_auto_commit=False 라면 commit 함수로 명시적으로 offset 위치를 커밋해야함
from kafka import KafkaConsumer
from json import loads
from time import sleep
consumer = KafkaConsumer(
'topic_test',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest', # 가장 처음 데이터부터 읽기
enable_auto_commit=True, # 자동 offset 커밋
group_id='my-group-id',
value_deserializer=lambda x: loads(x.decode('utf-8'))
)
for event in consumer:
event_data = event.value
print(event_data)
sleep(2)실행 방법
# bash에서
pip3 install kafka-python
python producer.py
python consumer.py

'Kafka & Spark Streaming' 카테고리의 다른 글
| Spark Streaming과 Kafka 연동 (0) | 2025.02.22 |
|---|---|
| Kafka 기본 프로그래밍 (0) | 2025.02.22 |
| Kafka소개 (0) | 2025.02.21 |
| 실시간 데이터 처리 소개 (0) | 2025.02.20 |